Yapay zekâ alanında gelişmelerin hızını takip etmek gün geçtikçe zorlaşıyor. Belki de teknolojik açıdan 2022’den itibaren yaşadığımız dönem, müthiş bir devinim çağına işaret ediyor. Thomas Kuhn’un bilimi devrimler olarak tanımladığı bir süreci yaşıyor gibiyiz. Gün geçmiyor ki henüz yeni oturmuş bir paradigma hızla demode olsun ve yeni paradigmalar kendine yer bulsun. Eko sistemde çoğunlukla taşlar yerine biraz dahi oturmadan, bütün yapı toptan bir kez daha değişiyor ve yeniden sindirme periyoduna giriliyor.
Bu dönemde özellikle AI ile ilgili hype (şişirme) döngüsünün gerçeklik ile bağlantısının önemli ölçüde koptuğunu görüyoruz. Bu durum İngilizce yazan alan uzmanları tarafından AI malaise olarak adlandırılıyor ve gün geçtikçe yapay zekâ modellerinin yarattığı “wow” hissinin azalması anlamına geliyor. Modeller özelinde düşünüldüğünde ise eğitildiği bilgiler ile tekrar eğitilen modellerin yenilik sunma imkânlarının daralması da bu sıradanlaşmaya bağlanabilir.
Sonuç olarak, modellerin gelecekte nasıl bir dünya şekillendireceğiyle ilgili iyimserlik artarken, gelecekle ilgili tedirginlik de hızla artıyor.
İşte böyle bir ortamda kurum olarak yapay zekâ yatırımlarınızın ne kadar gerçek değer yarattığını anlayabilmeniz için piyasanın durumunu algılamanız önemli hale geliyor. Stanford Üniversitesi tarafından yayınlanan AI Index Report 2026, bu dönüşüm çağında kurumlara ve araştırmacılara yol göstermeye çalışıyor.

AI Index Report, Stanford Üniversitesi’nin İnsan Merkezli Yapay Zekâ Enstitüsü (HAI) bünyesinde 2017’den bu yana yıllık olarak yayımlanan bağımsız bir değerlendirme raporu; 2026 baskısı dizinin dokuzuncusu. Temel özelliği, AI alanında çoğu verinin teknolojinin başarısından çıkarı olan kuruluşlar tarafından üretildiği bir ortamda tarafsız ve titiz ölçüm sunmak; bu nedenle politika yapıcılar, araştırmacılar, yöneticiler, gazeteciler ve kamuoyu için referans niteliği taşıyor. Araştırmacılar dünya çapında titiz bir araştırma yaparak en iyi ölçülen metriklerden politika önerileri çıkarmaya çalışıyorlar.
Dilerseniz bu yılki sonuçlar üzerine kısa bir değerlendirme yapalım. Index raporu; internet, PC gibi teknolojilerin tersine henüz geniş kitlelere duyurulmasının üzerinden üç yıl geçmeden üretken yapay zekânın toplumun %53’üne ulaştığının altını çiziyor. Kurumsal adaptasyon ise %88 seviyesinde. Eğitim tarafında ise her beş üniversite öğrencisinden dördü, eğitimlerinde bu modelleri kullanmakta.
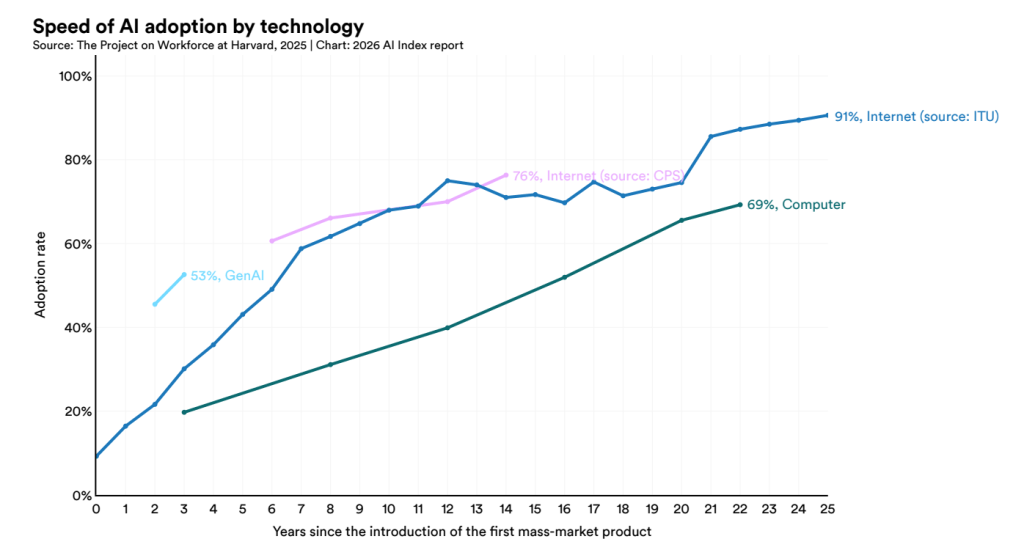
Toplam nüfus içerisindeki yapay zekâ kullanımının yaygınlığına baktığımızda ise, BAE ve Singapur gibi görece küçük ülkeler ihmal edildiğinde, halkın %40’ından fazlasının üretken yapay zekâ kullandığı İrlanda, Norveç ve Fransa’nın önde giden ülkeler olduğunu görüyoruz. İlginç ancak üretken yapay zekâ modellerinin çoğunu üreten ülke ABD’de kullanımın yaygınlaşmasının %26 seviyesinde kaldığını görüyoruz.
Öte yandan, dikkate değer denebilecek 95 modelin 88 adedi ticari şirketler tarafından üretilirken, akademinin sahibi olduğu model sayısı sadece 1. Ayrıca, bu 95 modelin tek başına 19 adedi OpenAI tarafından dağıtılmakta iken, 12 adedi ise Google tarafında geliştirilmiş durumda. Dikkat çekici olarak, önde gelen 50 modelin, 20 adedi Çin tarafından yayınlanmış durumda. En başarılı Amerikan modeli ile en başarılı Çin modeli arasındaki farkın 2,7 puana kadar düşmüş olması gelecekte yapay zekâ yarışının iki öncünün liderliğinde devam edeceğini gösteriyor.
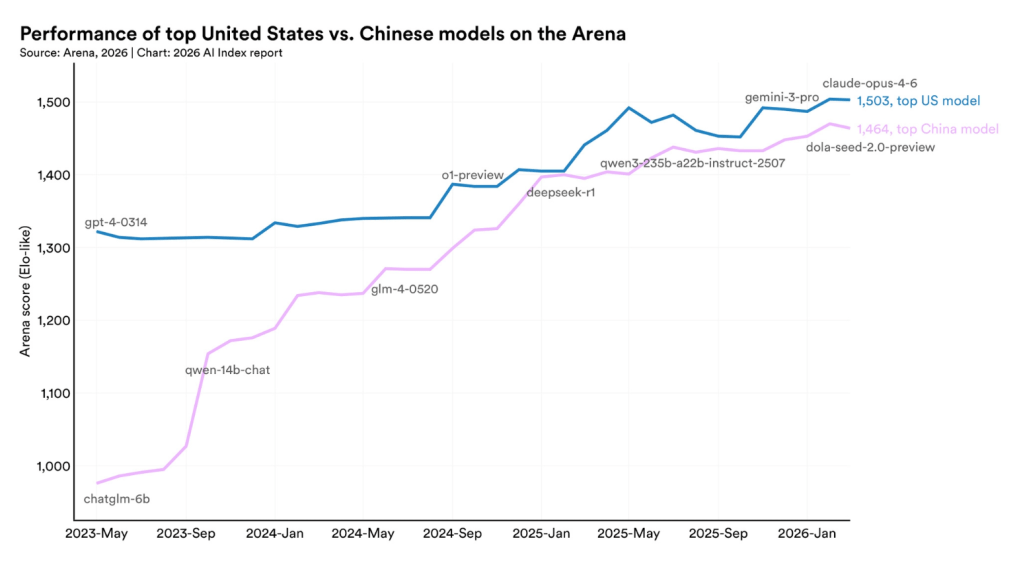
Rapor, mevcut modellerin performansını Berkeley Üniversitesi’ndeki araştırmacıların geliştirdiği ve her modelin önceden belirlenmiş bir soru setine göre test edildiği Arena_LM panelinin değerlendirmesini kullanıyor. Arena, milyonlarca anonim kullanıcının oylamasını satrançtan ödünç alınan Elo skoruna dönüştürerek modellerin performansını canlı bir tablo olarak paylaşıyor. Mart 2026 itibarıyla bu alanda Anthropic modellerinin performans sıralamasında üst sıralarda yer aldığını görüyoruz. Diğer önemli oyuncular olan xAI, Google ve OpenAI ise liderin hemen 10 ile 15 puan gerisinde çok sıkışık bir alanda toplanmış durumda. Çin kaynaklı Alibaba ve Deepseek modelleri ise 50 puan kadar geriden takip ediyor.
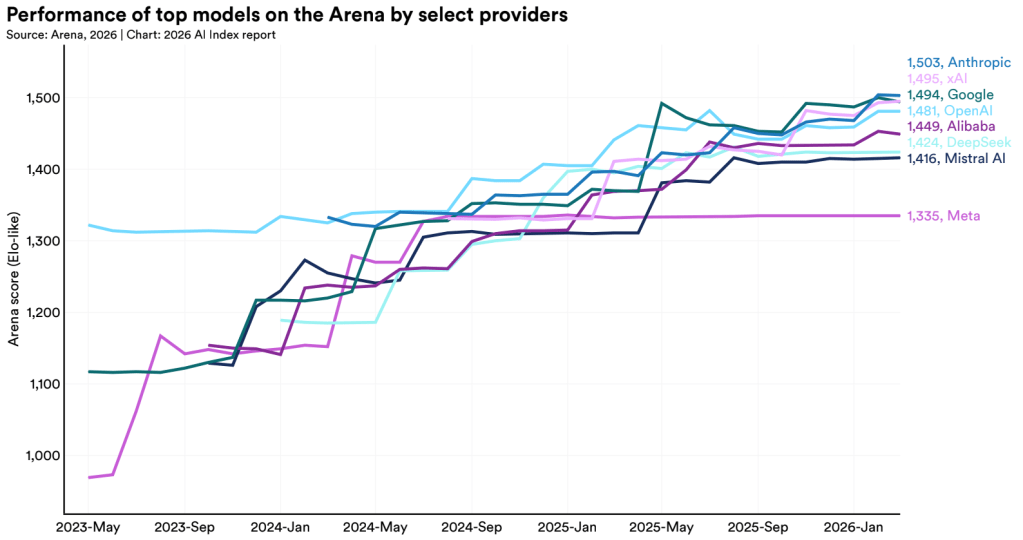
Önde gelen teknoloji şirketleri arasında bu yarışta en geride kalanın Meta olduğu görülüyor.
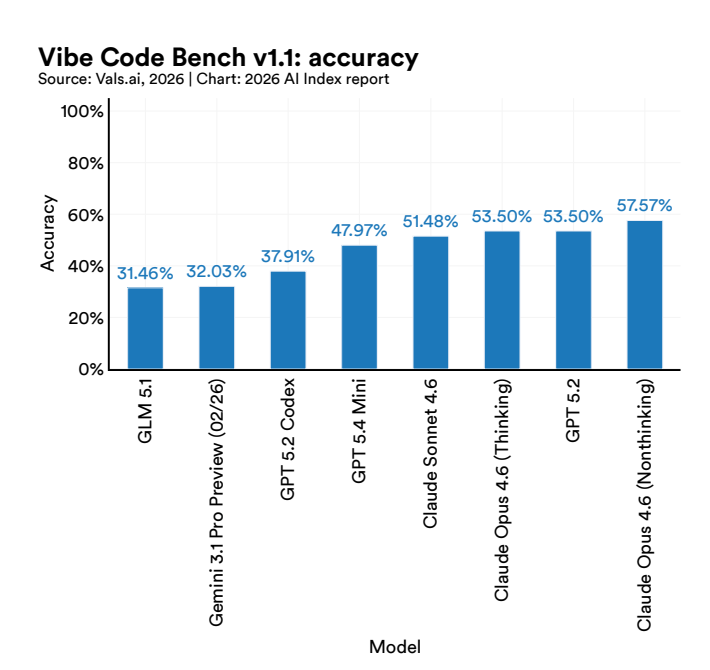
Öte yandan, benim gibi veri bilimi alanında çalışanların ilgisini en çok çeken taraf kod yardımcıları, dolayısıyla vibe coding şampiyonları. Burada liderlik %57 doğruluk veren Claude Opus (Non-Thinking) versiyon olurken, Google Gemini lideri neredeyse 20 puan geriden takip ediyor. Öte yandan bütün kod yardımcılarında uçtan uca aynı özellikte web sitesi dizaynını yapması istendiğini düşünürsek, tümden otonom kodlamanın henüz ulaşılması zor bir hedef olduğunu söyleyebiliriz.
Çeşitli danışmanlık alanlarında hangi modelin performansının öne çıktığını incelemek belki ilginç olabilir. İlk olarak finans alanında birçok görev için Google, Claude ve OpenAI modelleri çok yakın doğruluk puanları alıyor. Öte yandan, hukuk alanında OpenAI ChatGPT 5.1 öne çıkıyor.
Ajan temelli yapay zekâ işlemlerinde yine Claude Opus 4.6 birinciliği alırken, Alibaba’nın ücretsiz bir modeli olan Qwen 3.5’in bu alanda üst sıralarda kendine yer bulması dikkat çekici. Ajan temelli işlemlerin yüksek token maliyetine neden olması ve yapay zekâ kullanıcılarının yoğun olarak Claude Opus kredilerinin çok hızlı tükenmesinden şikâyet ediyor olması Qwen’in başarısına biraz daha önem katıyor.
Raporda modellerdeki performans artışının çoğunlukla mevcut veri setinin kalitesindeki düzelmeden de etkilendiği belirtiliyor. Bu nedenle, önümüzdeki dönemde kurumların alışılmış veri yönetişimi uygulamalarının dışına çıkarak, aynı zamanda yapay zekâ için hazır veri olarak adlandırabileceğimiz bir inisiyatif almaları gerektiğini söyleyebiliriz.
Raporun sonuna doğru gelirken, eğitimde yapay zekânın yerine değinelim. Neredeyse ABD’deki lise ve yükseköğretim öğrencilerinin %80’i okulda yapay zekâ kullanır hale gelmiş olmasına rağmen öğretmenlerin sadece %6’sı yapay zekâ ile ilgili kuralların net olduğunu söylüyor. Araştırmalar yapay zekâ mühendisliği yetkinliklerinin en çok Şili, BAE ve Güney Afrika’da arttığını gösterirken, ABD’de son iki senede yapay zekâ konulu doktora çalışmalarında %22 artış olduğunu görüyoruz. Ancak bu etki, yapay zekâ alanında fakülte pozisyonlarının sayısının artmasından çok, özel sektörde çalışma imkânlarının artmasından kaynaklanıyor.
Nihayet raporun içerisinde Türkiye ile ilgili ne saptamalar yapılmış konusuna gelirsek, göreceli yapay zekâ beceri yaygınlığı oranında 1,28 puan ile Türkiye, dünya ortalamasının üzerinde görülüyor. Türkiye bu alanda Hollanda, Polonya, İtalya gibi ülkeleri geçmiş gibi görünüyor. Bu endekste ilk üç sırayı açık ara liderlik ile Hindistan ve onu izleyen ABD/Almanya paylaşıyor. İsrail, BAE, Singapur gibi ülkeler ise Türkiye’den daha yüksek yaygınlık oranlarına sahipler. Türkiye neredeyse teknoloji ile ilgili her alanda olduğu gibi treni tamamen kaçırmış değil, ancak yağay zeka teknolojisini üreten iki ülke ve yoğun olarak yaygınlaştıran bir elin parmaklarını geçmeyecek kadar öncü ülke arasında değil. Daha önce TUIK’in yapay zeka istatistikleri ile ilgili yazdığım yazıda Türkiye’deki vaziyet üzerinde detaylı olarak durduğum için bu yazıda ülkemiz hakkında detaylı bir değerlendirme yapmayacağım.
Sonuçlar
Stanford 2026 yapay zekâ raporu, teknolojinin olağanüstü bir hızla ilerlemesine karşın, bu teknolojiyi yönetmesi gereken yönetişim çerçeveleri, güvenlik testleri, eğitim sistemleri ve veri altyapılarının bu hıza ayak uydurmakta ciddi şekilde zorlandığını ortaya koyuyor. Bu durum yapay zekânın yapabildikleri ile bizim yönetebildiklerimiz arasında büyük bir hazırlık uçurumunun oluşmasına neden oluyor. Öte yandan, yapay zekânın mevcut performans ve doğruluk testleri henüz her şeyi otonom süreçlere bırakmak için erken olduğunu ve human-in-the-loop olarak isimlendirilen, basiretli insan gözlemcinin yapay zekâ karar alma süreçlerinin başında kalmasına ihtiyaç olduğunu göstermekte.
Rapor yaklaşık 500 sayfadan oluşmakta ve bu blog sayfasında sizinle ancak kısıtlı bir bölümünü paylaşabiliyorum. Dilerseniz aşağıdaki link üzerinden ayrıntılı araştırma sayfasına ulaşabilirsiniz.
https://hai.stanford.edu/assets/files/ai_index_report_2026.pdf: Üretken yapay zeka teknolojisinin görünümü : İkinci Yıl
Leave a comment